

Harness Engineering in a Nutshell
A practical guide with context


There has been a lot of discussion about harness engineering lately — an aspect of building agents that I’ve been thinking for a while, as it bridges LLMs with traditional software engineering best practices.
It started with Mitchell Hashimoto (creator of Terraform and Ghostty), who gave the practice its name: “anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again.”
Then OpenAI published a detailed account of building a million-line production application over five months with zero hand-written code. Their conclusion: “the engineer’s job shifted from implementation to system design.” Martin Fowler picked it up, noting that the OpenAI piece buries its own lead — “harness” appears once in the text, yet the concept is the entire point. Anthropic’s engineering team approached the same problem from the other direction: agents that forget everything between sessions, like engineers working in shifts with no handoff. Their solution was structured persistence — a progress artifact that survives across context windows. And LangChain proved the numbers: their coding agent improved from 52.8% to 66.5% on Terminal Bench 2.0 by changing only the harness, with the model held fixed.
Latent Space’s swyx recently asked the hard question: is harness engineering even real? The piece frames the central tension well — Big Model vs Big Harness. The Big Model camp (Boris Cherny on Claude Code: “all the secret sauce is in the model — this is the thinnest possible wrapper”; Noam Brown: “those scaffolds will just be replaced by the reasoning models becoming more capable”) argues that better models make harnesses obsolete. The Big Harness camp counters that the harness is the product — every production agent converges on the same core loop, and the difference between a reliable system and a flaky one lives entirely in what wraps that loop. Swyx lands somewhere in the middle, noting that Cursor’s $50B valuation is hard to dismiss as pure model credit.
I come down firmly on the side of the harness — and not just because it’s generalizable. Harness engineering is good software engineering. It’s a clean separation of concerns: the model reasons, the harness controls. Verification nodes, constraint enforcement, structured handoffs — these are decomposed, testable modules, not prompt hacks buried inside a monolithic agent. The functional safety industry has known this for decades: you don’t make a safety-critical system reliable by making its core component smarter. You add redundancy, independent validation monitors, and enforced boundaries between layers. The harness is that architecture applied to AI agents. It’s also the most practical quality control mechanism we have — if your agent can produce output that bypasses verification, you don’t have a quality standard, you have a “suggestion” (like traffic lights in Greece).
The discussion so far has focused almost entirely on coding agents and long-running software projects. The principles apply anywhere agents do multi-step autonomous work — RAG pipelines, research synthesis, data processing, content generation. It’s worth making them concrete for AI engineers who aren’t building the next Codex but do want to build agents that actually hold up.
From in-context learning to harness engineering
It started with prompts.
When GPT-3 landed in 2020, the discovery that changed everything wasn’t the model itself — it was in-context learning: the ability to shape behavior by placing examples directly in the prompt. No fine-tuning, no retraining. Just carefully chosen text in the right position.
Researchers quickly found that structure mattered enormously. Chain-of-thought prompting (Wei et al., 2022) showed that asking models to reason step-by-step before answering — rather than predicting the answer directly — dramatically improved performance on complex tasks. Few-shot examples outperformed zero-shot. Explicit formatting beat freeform requests. The model hadn’t changed; what changed was the context it operated in.
This gave rise to context engineering: the discipline of curating what the model sees. What documents to retrieve. How to structure the system prompt. How much history to include. Context engineering is essentially asking: what information should the agent have access to right now?
It’s necessary. But it turns out it isn’t sufficient.
As agents became capable of sustained autonomous work — multi-step, multi-session, long-horizon tasks — a different class of failures emerged. Not hallucinations or bad reasoning, but structural failures: agents drifting from the original spec, declaring premature success, losing track of state between sessions, picking the wrong tool for the job.
Harness engineering is the response to that gap.
Context engineering vs. harness engineering
The distinction is worth making precise.
Context engineering asks: what should the agent see? Harness engineering asks: what should the system prevent, measure, and correct?
Context is a prerequisite. The harness is what turns a capable model into a reliable system. You need both — but most teams invest heavily in the first and neglect the second or confuse it with “business logic that the model will take care of” so they think the harness is their prompts.
Based on the above literature and my own agentic app projects, I believe harness engineering comes down to basically five patterns we can apply to our agentic apps. With the help of my new best friend, named Claude, I include examples below that use a RAG pipeline agent (building and evaluating retrieval over a writing corpus) rather than a coding agent — to make the principles concrete. The orchestration uses LangGraph; the retrieval layer uses Qdrant. The patterns themselves are framework-agnostic. Let’s walk through them.
1. Decompose before you execute
Without explicit task decomposition, agents given a broad goal will try to execute it in a single pass. They run out of context mid-implementation, leave half-finished work, and the next session’s agent spends most of its time reconstructing what happened rather than making progress.
The fix isn’t “work step by step” in the prompt. It’s a dedicated planning phase that produces a structured, machine-readable task list before any execution begins. A supervisor agent decomposes the goal; a worker processes one task at a time.
State definition and task structure:
from typing import TypedDict, Literal
from pydantic import BaseModel
class ProjectState(TypedDict):
goal: str
tasks: list[dict] # Each: {id, description, status, output}
current_task_index: int
artifacts: dict
class Task(BaseModel):
id: str
description: str
status: str = "pending"
class TaskList(BaseModel):
tasks: list[Task]
The planner — runs once, produces the list:
def planner(state: ProjectState) -> ProjectState:
task_list = llm.with_structured_output(TaskList).invoke(
f"""Decompose this project into 5-8 sequential tasks.
Each task should be completable independently.
Goal: {state['goal']}"""
)
return {
"tasks": [t.model_dump() for t in task_list.tasks],
"current_task_index": 0,
}
The worker — executes exactly one task:
def worker(state: ProjectState) -> ProjectState:
idx = state["current_task_index"]
task = state["tasks"][idx]
result = llm.invoke(
f"Complete this task. Only this task, nothing else.\n"
f"Task: {task['description']}\n"
f"Previous outputs: {state['artifacts']}"
)
state["tasks"][idx]["status"] = "done"
state["tasks"][idx]["output"] = result.content
return {"tasks": state["tasks"], "current_task_index": idx + 1}
The router — finds the next pending item:
def pick_next(state: ProjectState) -> Literal["worker", "__end__"]:
for task in state["tasks"]:
if task["status"] == "pending":
return "worker"
return "__end__"
Wiring the graph:
graph = StateGraph(ProjectState)
graph.add_node("planner", planner)
graph.add_node("worker", worker)
graph.add_edge(START, "planner")
graph.add_conditional_edges("planner", pick_next)
graph.add_conditional_edges("worker", pick_next)
app = graph.compile()
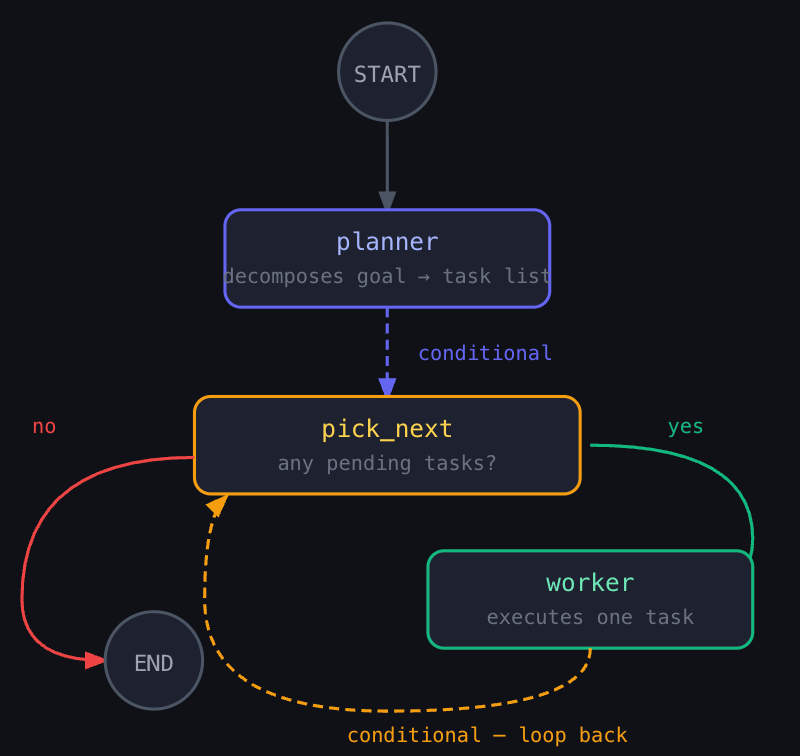
For a RAG pipeline project, the planner might produce:
[
{"id": "1", "description": "Ingest essays and chunk with semantic splitter"},
{"id": "2", "description": "Create Qdrant collection and index dense embeddings"},
{"id": "3", "description": "Implement BM25 sparse retrieval baseline"},
{"id": "4", "description": "Implement hybrid search with reciprocal rank fusion"},
{"id": "5", "description": "Build LLM-as-judge evaluator with 20 test queries"},
{"id": "6", "description": "Run evaluation across all three strategies and compare"}
]
The agent now has a contract. It processes one task, marks it done, and routes to the next. No skipping, no one-shotting the whole project.
2. Persist state across sessions
Each new session begins with no memory of previous sessions. Without a structured handoff, agents spend half their time reconstructing what happened instead of making forward progress.
The solution isn’t conversational memory or chat history. It’s a persistent artifact — stored externally — that the agent reads at the start of each session and writes to at the end. The references mention JSON works better than Markdown here: agents are less likely to accidentally overwrite structured data.
LangGraph’s Store abstraction handles this cleanly — a key-value layer that lives outside the graph’s ephemeral state and survives across invocations.
Session bookends:
from langgraph.store.memory import InMemoryStore
# In production: use Redis, Postgres, or another persistent backend
store = InMemoryStore()
def session_start(state: ProjectState, *, store) -> ProjectState:
progress = store.get(("project", "rag_pipeline"), "latest")
if progress:
return {
"tasks": progress.value["tasks"],
"current_task_index": progress.value["current_task_index"],
"artifacts": progress.value["artifacts"],
}
return state # First session: pass through to planner
def session_end(state: ProjectState, *, store) -> ProjectState:
completed = sum(1 for t in state["tasks"] if t["status"] == "done")
store.put(
("project", "rag_pipeline"),
key="latest",
value={
"tasks": state["tasks"],
"current_task_index": state["current_task_index"],
"artifacts": state["artifacts"],
"summary": f"{completed}/{len(state['tasks'])} tasks complete",
"retrieval_context": {
"qdrant_collection": state["artifacts"].get("collection_name"),
"embedding_model": state["artifacts"].get("embedding_model"),
"chunk_strategy": state["artifacts"].get("chunk_strategy"),
},
},
)
return state
Wiring them as bookends (sandwich the agent):
graph.add_edge(START, "session_start")
# Route to planner on first run, or skip straight to pick_next if resuming
graph.add_conditional_edges("session_start", lambda s: "pick_next" if s.get("tasks") else "planner")
graph.add_edge("worker", "session_end")
graph.add_conditional_edges("session_end", pick_next_or_end)
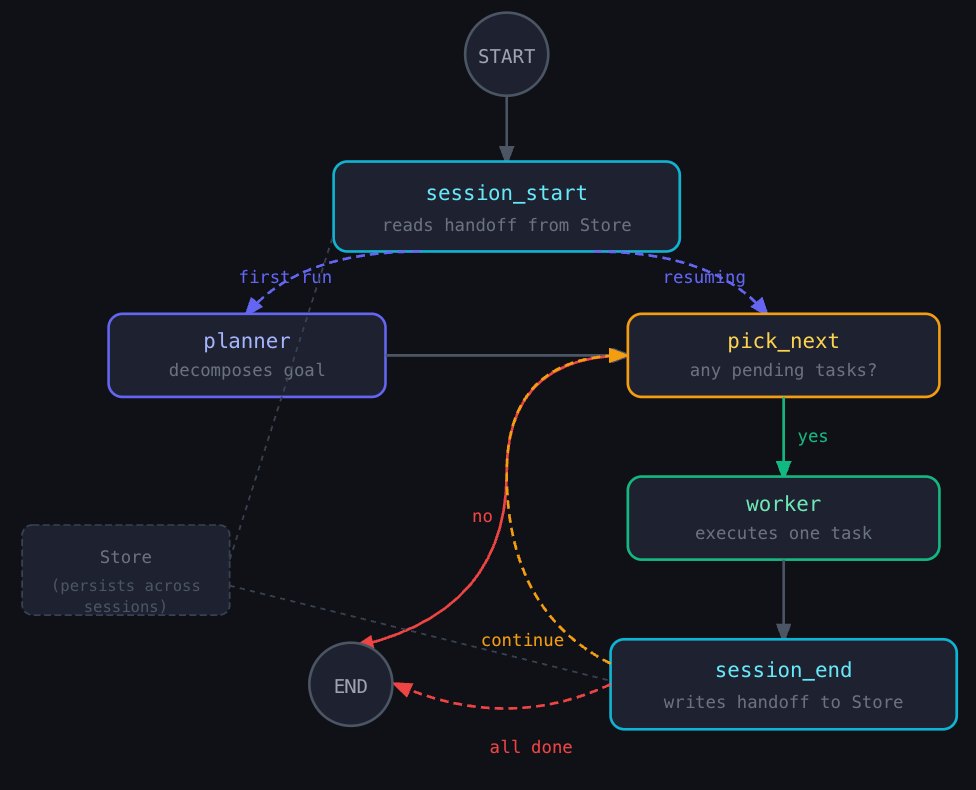
When session 2 starts, the agent reads structured JSON: tasks 1–3 done, task 4 pending, Qdrant collection is personal_writing_v2, embedding model is text-embedding-3-small. It doesn’t explore or guess. It picks up exactly where it left off.
3. Verify before moving on
The most common failure pattern in autonomous agents is that the agent produces output, re-reads it, decides it looks fine, and moves on. It never actually tests whether the output works. The equivalent of a developer who reads their code but never runs it.
The fix is explicit verification nodes in the graph — between the worker and the next task. Two flavors work best in combination.
LLM-based verification — checks against the spec:
class VerificationResult(BaseModel):
passed: bool
issues: list[str]
def verify_with_llm(state: ProjectState) -> ProjectState:
idx = state["current_task_index"] - 1
task = state["tasks"][idx]
verdict = llm.with_structured_output(VerificationResult).invoke(
f"""You are a reviewer. Does this output satisfy the task spec?
TASK: {task['description']}
OUTPUT: {task['output']}
Check: completeness, correctness, and whether the next task can build on it.
Return: passed (bool), issues (list of strings)"""
)
if not verdict.passed:
task["status"] = "needs_fix"
task["issues"] = verdict.issues
return {"tasks": state["tasks"]}
Deterministic verification — checks that retrieval actually works:
def verify_retrieval(state: ProjectState) -> ProjectState:
idx = state["current_task_index"] - 1
task = state["tasks"][idx]
if "qdrant" not in task["description"].lower():
return state # Skip for non-retrieval tasks
client = QdrantClient(url="localhost:6333")
# embed() wraps your embedding model, e.g. OpenAIEmbeddings etc.
results = client.query_points(
collection_name=state["artifacts"].get("collection_name"),
query=embed("What are my thoughts on creative writing?"),
limit=5,
)
scores = [r.score for r in results.points]
issues = []
if len(scores) == 0:
issues.append("Retrieval returned zero results")
elif scores[0] < 0.5:
issues.append(f"Top score {scores[0]:.2f} below threshold — check embedding config")
if issues:
task["status"] = "needs_fix"
task["issues"] = issues
return {"tasks": state["tasks"]}
Routing the loop:
def after_verify(state: ProjectState) -> Literal["worker", "pick_next"]:
idx = state["current_task_index"] - 1
if state["tasks"][idx]["status"] == "needs_fix":
return "worker"
return "pick_next"
graph.add_edge("worker", "verify_retrieval")
graph.add_edge("verify_retrieval", "verify_with_llm")
graph.add_conditional_edges("verify_with_llm", after_verify)
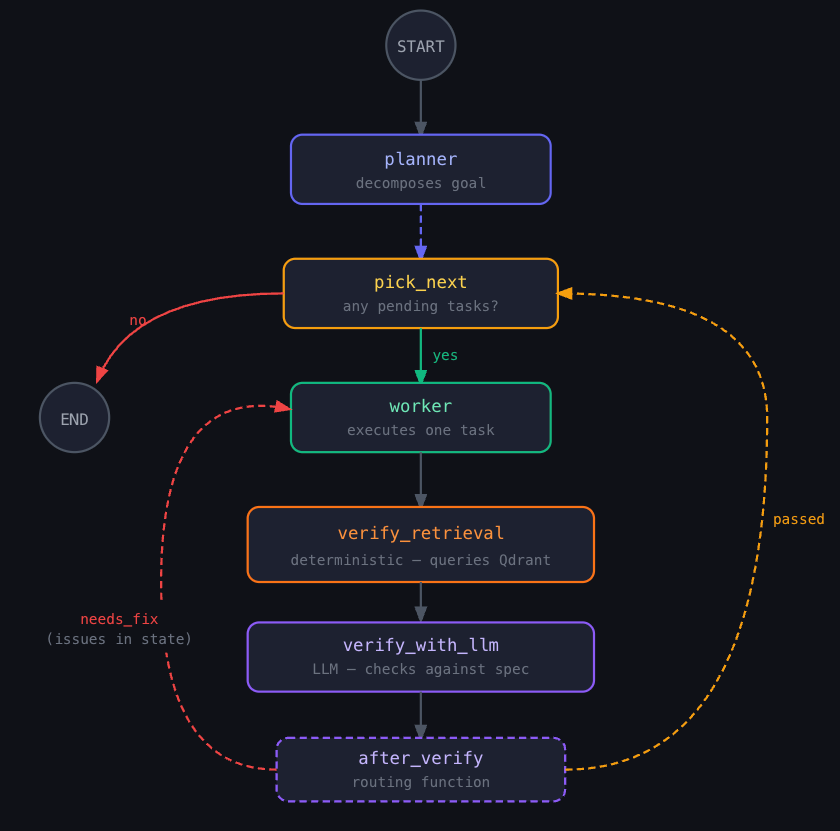
The critical detail: when control loops back to the worker, the issues list is in the state. The worker reads specific failure reasons and addresses them — not a generic retry.
4. Enforce constraints mechanically
Verification asks whether the output is correct. Enforcement asks whether the agent violated any structural rules — regardless of output quality.
OpenAI’s team used custom linters for their coding agents. The key insight: error messages were written to double as remediation instructions that get injected back into agent context. The system wasn’t just blocking mistakes; it was teaching the agent while it worked.
In LangGraph, this is a pure Python node — no LLM call — placed at a mandatory point in execution. The graph topology guarantees it runs; the agent cannot skip it.
def enforce_constraints(state: ProjectState) -> ProjectState:
"""No LLM. Runs after every worker output."""
idx = state["current_task_index"] - 1
task = state["tasks"][idx]
violations = []
# Chunking boundaries
if "chunk_size" in state["artifacts"]:
size = state["artifacts"]["chunk_size"]
if not (100 <= size <= 2000):
violations.append(
f"VIOLATION: chunk_size={size} outside [100, 2000]. "
f"FIX: Below 100 loses semantic coherence; above 2000 "
f"exceeds embedding model input limits."
)
# Qdrant vector dimensions
if "collection_config" in state["artifacts"]:
config = state["artifacts"]["collection_config"]
if config.get("vector_size") != 1536 and \
"text-embedding-3-small" in str(state["artifacts"].get("embedding_model", "")):
violations.append(
f"VIOLATION: vector_size={config.get('vector_size')} but "
f"text-embedding-3-small expects 1536. "
f"FIX: Set vector_size=1536 in the Qdrant collection config."
)
# Evaluation metric sanity
if "eval_scores" in state["artifacts"]:
for metric, score in state["artifacts"]["eval_scores"].items():
if not (0.0 <= score <= 1.0):
violations.append(
f"VIOLATION: {metric}={score} outside [0, 1]. "
f"FIX: Normalize the evaluator's scoring function."
)
if violations:
task["status"] = "needs_fix"
task["constraint_violations"] = violations
return {"tasks": state["tasks"]}
The mandatory execution pipeline after every task:
graph.add_edge("worker", "enforce_constraints") # always runs
graph.add_edge("enforce_constraints", "verify_retrieval")
# verify_retrieval → verify_with_llm and after_verify routing already set in Pattern 3
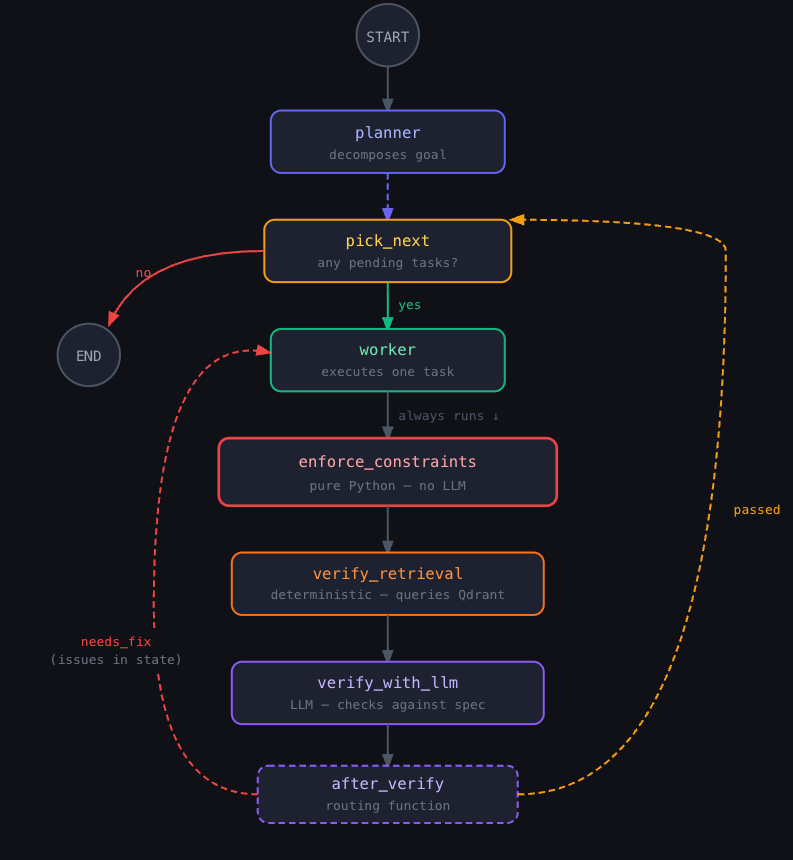
The agent cannot create a Qdrant collection with the wrong vector dimensions and proceed. The constraint node will catch it and return explicit remediation steps (that the after_verify step will see and go to needs_fix. Structure that’s impossible to bypass — through prompting or otherwise. And it most likely save you some wasted tokens and $$ before piling up bad outputs from bad inputs.
5. Design tools with decision criteria, not just descriptions
Binding tools to an agent at initialization is table stakes. What changes outcomes is how you describe them.
Jeff Huber (CEO of Chroma) argues for narrow tools with descriptions that encode decision criteria — not just what the tool does, but when to use it and when not to. Tool descriptions are part of the agent’s context at decision time. The LLM loads these descriptions in its context. Vague descriptions force the agent to figure out retrieval strategy on its own. Precise descriptions let it match the right tool to the task without trial and error.
from langchain_core.tools import tool
# client = QdrantClient(url="localhost:6333")
# embed() wraps your embedding model, e.g. OpenAIEmbeddings or sentence-transformers
@tool
def semantic_search(query: str, top_k: int = 5) -> list[dict]:
"""Search by meaning — use for conceptual queries where exact keywords
may not appear in the text.
WHEN TO USE: 'What do I think about creativity?' or 'passages about
self-doubt' — where the text might say 'imposter syndrome' instead.
HOW IT WORKS: Embeds the query with text-embedding-3-small and runs
cosine similarity against the personal_writing Qdrant collection."""
results = client.query_points(
collection_name="personal_writing",
query=embed(query),
limit=top_k,
)
return [{"text": r.payload["text"], "score": round(r.score, 3), "id": r.id}
for r in results.points]
@tool
def keyword_search(query: str, top_k: int = 5) -> list[dict]:
"""Search by exact terms — use for specific names, dates, technical
terms, or phrases the user quoted directly.
WHEN TO USE: 'mentions of Kahneman' or 'the paragraph about March 2024'.
HOW IT WORKS: BM25 sparse retrieval over the same corpus."""
...
@tool
def hybrid_search(query: str, top_k: int = 5, semantic_weight: float = 0.7) -> list[dict]:
"""Combined semantic + keyword search. Use this as the default when
unsure which approach fits.
WHEN TO USE: Most general queries. Start here unless you have a
specific reason to use the others.
HOW IT WORKS: Runs both searches, combines via reciprocal rank fusion."""
...
@tool
def get_full_document(doc_id: str) -> dict:
"""Retrieve the complete text of a document by ID.
WHEN TO USE: After seeing a doc_id in search results and needing
surrounding context.
DO NOT USE for discovery — use a search tool first."""
point = client.retrieve(collection_name="personal_writing", ids=[doc_id])
return {"text": point[0].payload["text"], "metadata": point[0].payload["metadata"]}
Three things each description does that generic descriptions don’t: decision criteria (WHEN TO USE), mechanism (HOW IT WORKS), and negative guidance (DO NOT USE for). The agent selects the right tool on the first try rather than defaulting to the most generic option or cycling through by trial and error.
The full picture
The five patterns compose into a single graph topology:
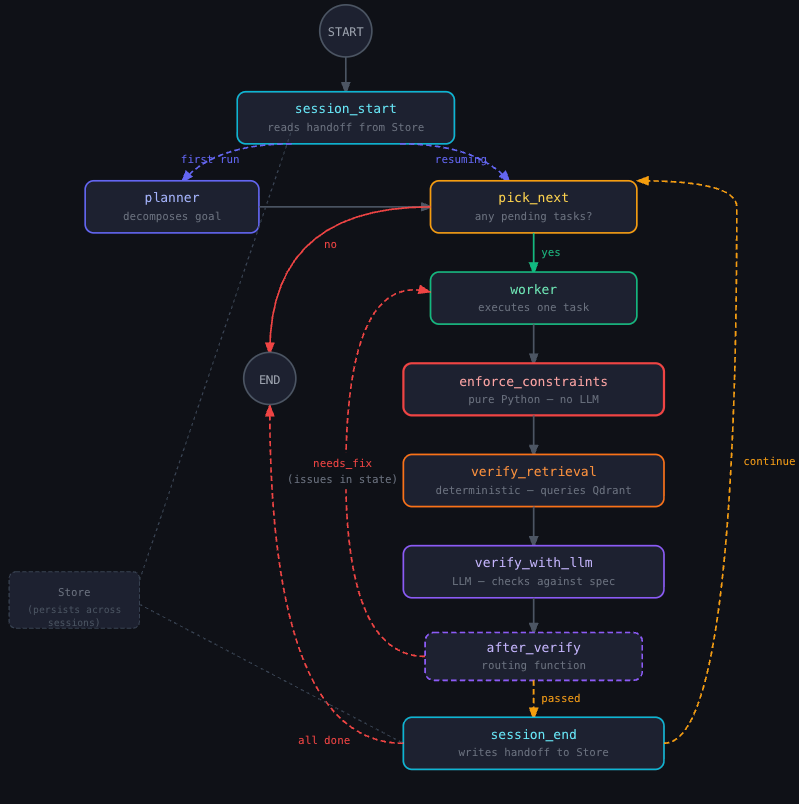
None of this requires a better model. LangChain demonstrated that concretely: their coding agent improved from 52.8% to 66.5% on a benchmark by changing only the harness, with the model fixed.
The model provides the intelligence. The harness determines whether that intelligence produces consistent, verifiable, recoverable work that’s easy to test.
I love that the community is thinking about this. We should stop thinking about AI Engineering as “art”. There is no reason we shouldn’t treat it like any other software engineering discipline.