

The Evolution of Software Engineering: From Assembly to Agents
A Framework for Understanding the Past and Predicting the Future


Every generation of programmers believes they’ve finally figured out the “real” way to write software.
Assembly programmers knew the machine. Procedural programmers knew algorithms. Object-oriented programmers knew design patterns. And today’s engineers? We know frameworks, APIs, and how to compose systems from a thousand npm packages.
Each generation was right—for their era.
But here’s the thing: every generation also got abstracted away. The assembly wizards watched compilers take over. The algorithm experts watched libraries commoditize their work. The design pattern experts watched frameworks encode their wisdom into configuration files and DSLs.
And now? We’re watching something similar happen again.
I’ve been thinking a lot about what “programming” will mean in five years. Or ten years. Not because I’m worried about AI taking jobs—that’s the wrong framing. I’m curious because I expect a pattern will emerge. The same pattern that’s played out five times before in computing history.
If we understand that pattern, we can predict what’s coming. And more importantly, we can prepare for it. Especially the next generation of engineers.
The Pattern: Abstraction All the Way Up
Here’s the core thesis: software engineering evolves through abstraction layers. Each new layer lets us express more with less. And each layer trades mastery of what’s below for the ability to manage greater complexity above because we can trust the collective best-in-class practices encoded by our tools to handle the layer below.
This isn’t a new idea. But I think we’re at an inflection point where it’s worth spelling out explicitly—because the next layer is going to change things more dramatically than any previous transition.
Let me walk through the six generations I see in software engineering history, and then we’ll talk about what comes next.
Generation 1: Assembly (1950s–60s)
In the beginning, there was the machine.
Early programmers didn’t write code—they wrote instructions. Opcodes, register addresses, memory locations. Every program was a precise sequence of commands that told the hardware exactly what to do, step by step.
Think about what that meant. To write software, you had to understand the physical machine. How many registers did it have? What was the instruction cycle? How did memory addressing work? The “abstraction” was... nothing. You were talking directly to the hardware.
Correctness meant one thing: did I use the right instructions to produce the right bits as efficiently as possible?
Getting to automate things was the big win then. This was incredibly powerful. And incredibly limiting. A single human could only hold so much machine state in their head. Programs were small by necessity—not because the hardware couldn’t do more, but because human cognition couldn’t track more.
But it worked. And for a while, this was programming.
Generation 2: Procedural (1970s–80s)
Then someone had a brilliant idea: what if we let a program write the machine code for us?
The compiler changed everything. Suddenly, you didn’t have to think about registers and memory addresses. You could write in a higher-level language—C, Fortran, Pascal—and the compiler would figure out the machine details.
The abstraction shifted from hardware instructions to control flow. Now you thought in functions, loops, and conditionals. The machine disappeared; logic remained.
Correctness meant something different: does this algorithm do what I intend?
Notice the trade-off. You gave up direct control of the hardware. Your compiled code was probably slower than hand-tuned assembly. But you gained the ability to write larger programs, to think at a higher level, to express intent more directly.
Was it worth it? Obviously yes. We’re still using compilers.
But here’s the interesting part: the compiler became a trusted collaborator. You verified your logic; it handled the translation. You didn’t need to check every line of assembly it produced. You trusted it. It was built by experts.
Remember that idea. It’s going to come back.
Generation 3: Object-Oriented (1990s–2000s)
As programs grew larger, a new problem emerged: managing state.
Procedural code was great for algorithms, but real applications had things—users, accounts, documents, transactions. These things had data and behavior. And managing them across a myriad of functions became a nightmare.
Object-oriented programming gave us a new abstraction: state encapsulation. Now you could model your domain with classes and objects. Data and behavior lived together in Abstract Data Types. Interfaces defined contracts. Inheritance let you share and specialize and model the world.
The abstraction shifted again. You stopped thinking about procedures and started thinking about domain models. UML diagrams, design patterns, class hierarchies—these became the tools of the trade.
Correctness meant: do these components interact correctly?
And something else happened in this era: design separated from implementation. You could sketch a system in UML without writing a single line of code. Then hand it to implementers. This was new. Previously, design was implementation.
The Gang of Four patterns weren’t just clever tricks—they were a vocabulary for thinking about software at a higher level than code itself.
Generation 4: Composition (2000s–2010s)
By the 2000s, something shifted again. There were so many libraries, so many frameworks, so many services—why were we still writing things from scratch? Thank you Open Source!
The abstraction became capabilities. You stopped asking “how do I implement this?” and started asking “which library already does this?”
Think about what a modern web application looks like. You import a framework for routing. A library for state management. An ORM for the database. An SDK for payments. Another for authentication. You’re not implementing these things—you’re composing them.
Correctness meant: did I wrap everything correctly?
The senior skill changed. It wasn’t about knowing algorithms (though that still helped). It was about knowing the ecosystem. What libraries exist? Which ones are maintained? What are the trade-offs? The best engineers distinguished themselves by knowing what not to build.
This era gave us package managers, software development across borders, and… dependency hell. But it also gave us incredible productivity. A single developer could build things that previously required teams.
Generation 5: Declarative (2010s–2020s)
The next shift was more subtle but just as profound.
Terraform. Kubernetes. SQL. GraphQL. React’s declarative UI model. What do these have in common?
You describe what you want, not how to achieve it. The system figures out the execution.
(But wait. Didn’t HTML have the same thing going on already in the 90’s? Yes, but you still had to rely on Javascript to do anything really useful 🤷 )
Now, if I want three replicas of this container, with these resource limits, on these nodes, I don’t specify the scheduling algorithm. I don’t manage the container lifecycle. I declare the desired state, and the system converges toward it because it already has wrapped everything it needs.
The abstraction became desired state. You’re not writing procedures anymore—you’re writing specifications.
Correctness meant: does my specification match my intent?
This is a subtle but important shift. The “code” you write isn’t executed step by step. It’s interpreted as a description of what should exist. The runtime decides how to make it so.
GitOps emerged from this. Your infrastructure is a YAML file in a repo. Change the file, the system converges to match. Deployment becomes a pull request.
Generation 6: Agentic (2020s–?)
And now we’re at the edge of something new. The “vibes” as we have come to call it.
Large language models can write code. Not just snippets—entire applications. You describe what you want in natural language, and the model generates an implementation.
This isn’t just another tool. It’s a new abstraction layer.
The abstraction is intent itself. You’re not writing code, configuration, or even structured specifications. You’re describing what you want in the most natural way possible—plain language—and the system produces an implementation.
Correctness means: does the system satisfy my specifications under the conditions I care about?
Andrej Karpathy called it early. In January 2023, he tweeted: “The hottest new programming language is English.”
He was directionally right. But as we’ll see, it’s more nuanced than that.
The Rhyming Principles
Here’s what’s fascinating: every generation follows the same patterns. History doesn’t repeat, but it rhymes.
Let me spell out the principles that keep showing up:
Abstraction as compression. Each layer lets you express more with less. What took 100 lines of assembly became 10 lines of C, then one library call, then one config line. The direction is consistent: toward pure intent.
The performance-productivity trade-off. We consistently accept slower execution for faster development. Hardware cost decreases faster than developer cost. This has held for 60+ years. We’ll accept suboptimal generated code if it gets us to working software faster.
Verification moves up the stack. Each layer develops its own correctness tooling. Assembly had instruction traces. Procedural had debuggers. OOP gave us unit tests. Composition brought integration tests. Declarative uses policy validators. What will the agentic era need? It’s not just evals. We need more than that.
The one-layer-down rule. Effective practitioners understand the layer immediately below them. Web developers know HTTP but not TCP internals. App developers know APIs but not compiler internals. You need one layer down for debugging. But not deeper—that’s diminishing returns.
Debugging requires descent. Abstractions always leak. When they do, you must drop down. This is why one-layer-down knowledge remains essential—even in the agentic era.
Composition over construction. Senior engineers in every era distinguish themselves by knowing what not to build. The boundary keeps moving up, but the principle stays the same.
These patterns aren’t a coincidence. They emerge from fundamental constraints:
human biological cognition is finite
hardware gets cheaper
complexity wants to grow
The SDLC Rhymes Too
It’s not just the abstractions that rhyme. The entire software development lifecycle transforms at each layer—but the phases persist.
Design, build, test, optimize, deploy. These five activities exist in every generation. But what they mean changes completely.
Design started as hardware diagrams and instruction sequences. It became flowcharts, then UML, then architecture diagrams, then specs-as-code. In the agentic era? Natural language specifications, constraints, examples. The design artifact increasingly is the specification.
Build started as hand-coding punch cards. It became compilation, then complex build systems, then package managers, then reconciliation loops. In the agentic era? The agent generates, tests, iterates, refines. The human curates and approves.
Test started as manual traces and core dumps. It became print debugging, then unit tests, then integration tests, then chaos engineering. In the agentic era? Acceptance verification. Property-based tests. The agent critiquing its own output against success criteria.
Optimize started as hand-tuning assembly—choosing the right registers, minimizing instruction cycles, fitting code into scarce memory. It became compiler optimizations: dead code elimination, loop unrolling, inlining. In the composition era, it meant tree-shaking unused dependencies and minimizing bundle sizes. In declarative infrastructure, it’s right-sizing resources and optimizing reconciliation loops.In the agentic era? Optimization operates on source code itself. Not just for performance—for elegance and minimalism and code reuse, not slop.
Deploy started as physical media—tapes and cards. It became compiled binaries, then installers, then containers, then GitOps. In the agentic era? Continuous, agent-driven deployment. Maybe self-optimizing systems that adjust based on production telemetry.
The phases don’t disappear. They get automated or absorbed. The human role shifts from executor to specifier and verifier.
Why Writing Becomes the Core Skill
Now we get to the part that I think most people miss about AI-assisted development.
There’s a seductive idea floating around: natural language programming means lower cognitive demands. “Just describe what you want.” Sounds easy, right?
It’s actually the opposite.
Think about it. When you write code, the compiler enforces clarity. Syntax errors, type mismatches, failed tests—these are all feedback mechanisms that force you to sharpen your thinking. The code doesn’t run until your intent is precise enough.
When you write prose to an LLM? There’s no syntax error for ambiguity. The model will always produce something. It will cheerfully generate code from vague specifications, filling in gaps with assumptions you never examined.
The rigor that was externalized into the compiler must now be internalized into the specification process.
This is why “vibe coding”—Karpathy’s term for casual prompting without reviewing the output—works for weekend projects but won’t scale to production systems. It’s the toggle-switch programming of this era: fast for experiments, unmaintainable for anything real. LLMs are trained to statistically match features and similarities in concepts in our language so there is a limit to how vague we can be and get away with it. Our words are biasing the LLMs towards a particular direction vs another. Therefore err on the side of being specific and reduce ambiguity.
What Non-Programmers Teach Us
Here’s something interesting: when non-programmers learn to code—even with block-based visual languages like Scratch—they struggle in revealing ways.
The difficulty isn’t syntax. It’s something deeper.
Take the “implicit else” problem. A non-programmer writes an if-statement and assumes that if the condition isn’t true, the code will do “the other thing.” But in actual code, the program does nothing—it just continues to the next line. Maybe the assumption that “if I don’t specify then assume I mean the opposite” is ok for some people but not OK for others and the truth is somewhere in between the large amount of text that LLMs were trained with. It will think “it depends” and if it gets smarter it might ask you a question to disambiguate. If it wants to “please” you, it will just do what the statistics deem as most popular.
The above is a simple scenario. But think about it. It isn’t a syntax error. It’s a thinking error. Natural language allows implicit defaults. Computation requires explicit specification. Moving to natural language prompts doesn’t eliminate this problem. The LLM will also assume implicit defaults—and they may not match your assumptions.
“Make the button blue when clicked.” Okay, but what happens when it’s clicked again? Should it toggle? What shade of blue? What if the user doesn’t have permission? What if JavaScript is disabled?
The non-programmer’s struggle with explicit specification is the core challenge of agentic coding. The syntax barrier is removed. The thinking barrier remains for the untrained vibe coder.
The real skill was never syntax. It was thinking precisely enough that your intent could be unambiguously executed. Maybe the coders of the future will be trained in law schools? I mean why not? Their jobs will be taken over by AI soon. They might as well move to vibe coding. Even so, I hope not. I’d prefer philosophy grads or art majors in my 2035 engineering org.
The Sketching Paradigm
Why philosophy or art majors? Here’s where it gets interesting. LLMs do change something fundamental about the creative process—just not what most people think.
Traditional compilers demand premature rigor. Every line must be syntactically correct. Every type must match. You must be precise at the micro level before you can see the macro result.
This is like being required to paint in final detail before seeing the composition.
We’ve been fighting this forever. That’s why we built autocomplete, linting, real-time error highlighting, type inference, and hot reload. These tools exist because the compile-then-see-errors loop was too slow and punishing. We were trying to make coding feel more like sketching.
LLMs are the logical continuation. They let you skip the line-by-line negotiation entirely.
Think about how artists work. They start with rough sketches—capture the shape, ignore the details. They iterate on composition before committing to finish. The medium supports this workflow.
LLMs make code work this way too.
You can describe a pattern: “Build a user authentication flow with email verification.” The LLM produces a working sketch. It’s imperfect, but it’s runnable. You can see the shape before committing to the details. Then you can dive deeper as you reason the consequences.
This is why this new paradigm feels more accessible. It matches natural creative processes. It matches how senior engineers already think—progressive composition, sketching the API first, stubbing implementations, refactoring as understanding deepens.
The difference is that experienced engineers learned to do this despite the compiler’s demands. LLMs make it native to the medium. Novices can access the expert workflow from day one. And those trained in art or philosophy will do well above average. They create and experiment and test hypotheses systematically and most importantly they can articulate what “done” looks like. In the future, instead of doing that on paper or canvas, they can do it by turning the LLM into a compiler from NLP to Python, TS, C++, etc. and either sketching top down or setting the success criteria similar to a reward function, and eating up compute doing reinforcement learning until the outcome fits the bill.
The Technical Foundation
I should explain why this actually works at a technical level. Because “prompts are programs” isn’t just a metaphor—it’s literally true.
Few-shot learning (demonstrated in the GPT-3 paper, 2020) showed that you can change a model’s behavior by including examples in the prompt. No fine-tuning. No gradient updates. Just text.
The prompt isn’t a question—it’s a specification. The examples program the model’s behavior through “in-context learning”.
Chain-of-thought prompting (Wei et al., 2022) showed that you can make models execute reasoning procedures by showing them examples of reasoning. Include step-by-step problem-solving in your prompt, and the model will decompose new problems the same way.
The prompt describes how to compute, not just what to compute. It’s pseudocode in natural language.
ReAct (Yao et al., 2022) showed that prompts can specify interleaved reasoning and action patterns. The model reasons, takes an action, observes results, and adjusts its plan.
The prompt defines a control loop—a behavioral pattern that unfolds over time with environmental feedback.
See the progression? From questions to specifications to algorithms to control loops. Prompts have evolved from queries to complex computational specifications.
This is why the LLM layer fits the same pattern as every other compiler. It takes a higher-level specification and produces a lower-level implementation through an “algorithm”. The medium is natural language (one level closer to human expression vs machine expression), but the function is the same.
“English Is the New Programming Language”—Sort Of
So Karpathy was right. English is the new programming language.
But it’s more nuanced than that.
There are really two phases to agentic coding that have emerged:
Phase 1: Sketching. Express intent in natural language, get a working approximation. This is broadly accessible. It matches how people naturally communicate.
Phase 2: Refining. Identify gaps, specify edge cases, iterate to production quality. This requires precision. It’s specification engineering.
Both phases use natural language. But they require very different skills.
“Make it pop” gets you a first draft. “Handle the edge case where the user submits an empty form after the session timeout but before the page refresh” gets you production code.
Here’s what’s not obvious: when you clarify ambiguity in a prompt, you’re making design decisions. Each clarification is a specification choice. The refinement process is the design process.
People who think they’re “just describing what they want” are actually architecting systems. The more skillful they are in understanding the underlying building blocks the better agent-assisted coders they will be.
Two Ways to Sketch
But there’s another way to approach this entirely. Instead of sketching the solution and refining it, you can sketch the success criteria and let the agent search for solutions that satisfy them.
Think of it like reinforcement learning. Instead of telling the agent how to build something, you define what “done” looks like—your reward function—and let the agent explore until it finds something that meets your criteria.
Say you’re building a data pipeline. The traditional approach: “Build an ETL job that pulls from Postgres, transforms the data like this, and loads it into Redshift.” You’re specifying the solution.
The reward-based approach: “I need data in Redshift that matches these validation rules, refreshed within 15 minutes of the source, with less than 0.1% error rate, costing under $50/month to run.” You’re specifying the success criteria—the definition of done—and letting the agent figure out the implementation.
The agent might try different architectures. Batch vs. streaming. Different transformation strategies. It runs against your criteria, fails, adjusts, tries again. You’re not guiding the solution—you’re refining the reward function until it captures what you actually care about.
This is powerful for problems where you know the outcome but not the path. “I need a recommendation engine that increases click-through by 20%” is easier to specify than the exact algorithm to achieve it. Let the agent search.
Of course, there’s a trade-off. Solution sketching is fast—you get something immediately and iterate on it. Reward sketching requires more upfront thinking about success criteria, and the agent’s search process takes longer and costs more compute. You’re trading human iteration time for machine exploration time.
But here’s what’s interesting: as models get better and cheaper, the reward-based approach becomes more viable. And it forces a useful discipline. When you have to articulate your success criteria precisely—decompose them, weigh them, handle conflicts between them—you often discover you didn’t really know what you wanted in the first place. Classic TDD trade-off.
The skill isn’t just describing what you want. It’s defining success criteria that actually capture what you want within what’s possible by your building blocks—criteria robust enough that an optimization process can’t game them. I think we need to be able to work on both levels: sketching solutions or sketching success criteria. Both depend on the solid understanding of the layer below.
A better framing:
Conversational English is the new design language.
Specification-grade English is the new programming language.
And increasingly, success-criteria English is the new testing language.
The barrier to entry (sketching) is dramatically lower. The ceiling of skill (specification and criteria design) is just as high.
The New Full Stack
Let me sketch what the full pipeline looks like in the agentic era:
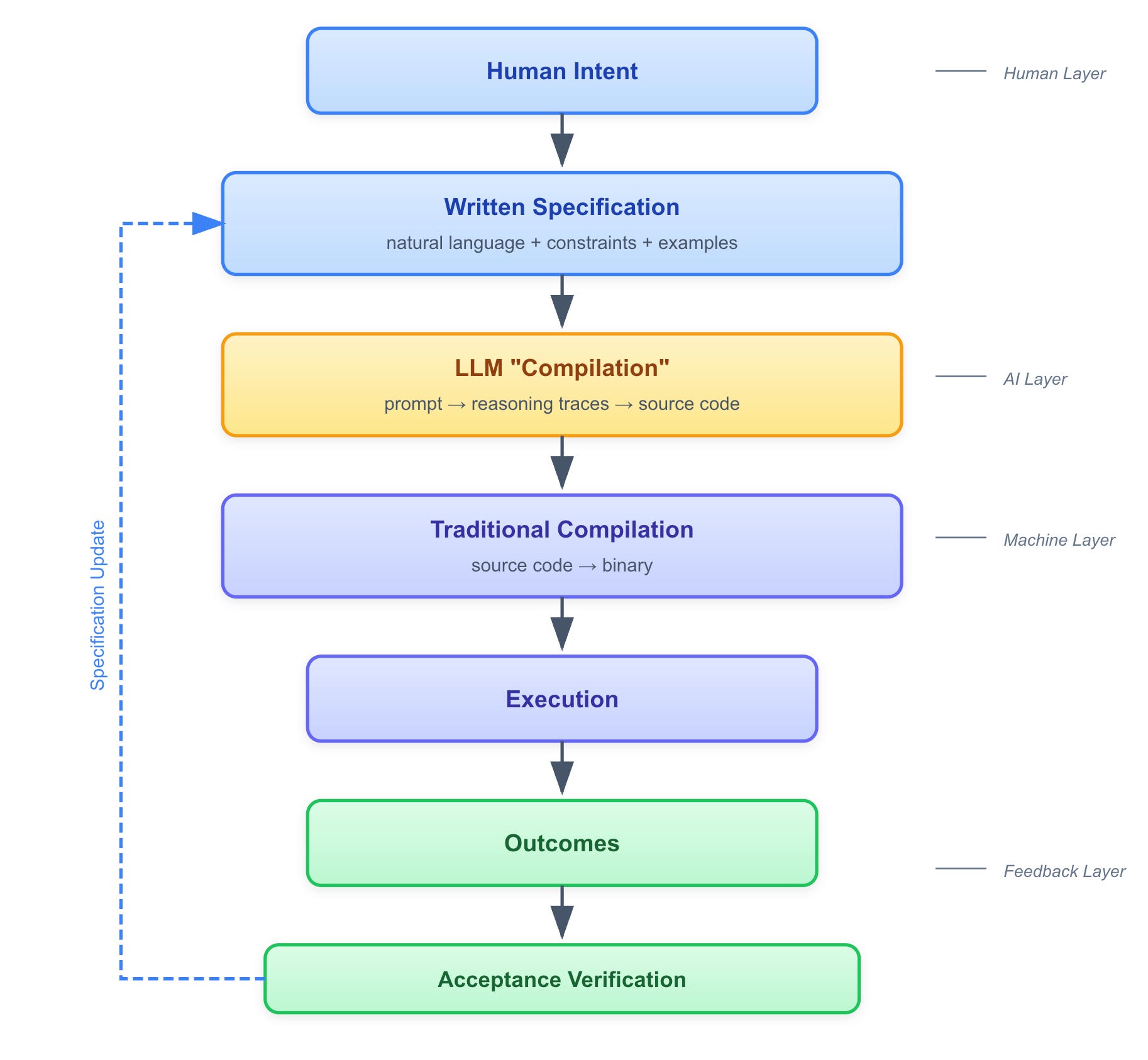
The critical insight: feedback must flow all the way back to the specification layer. Runtime behavior informs specification refinement. The loop closes at the top.
And here’s what the “compiler of the future” could look like. Not just a translator from high-level to low-level, but a bidirectional, multi-layer system:
Downward (generative): Specification → code → binary → execution
Upward (explanatory): “This timeout occurred because the generated code used algorithm X, which was chosen because your spec said Y, which implied constraint Z”
Lateral (suggestive): “If you want behavior A instead, modify your specification from P to Q”
This is possible because of the rhyming properties we discussed. Every layer has analogous concepts—correctness, composition, optimization, verification. A sufficiently capable system can translate between them.
The Tooling Gap
Here’s the problem: we don’t have the tools yet.
Every generation required new tooling for its abstraction layer. Assembly needed assemblers. Procedural needed compilers and debuggers. OOP needed IDEs and unit test frameworks. Composition needed package managers and CI/CD.
For the agentic era, we need:
Specification validators (the new compiler). Detect ambiguity: “Your spec could mean X or Y—which do you intend?” Detect incompleteness: “You haven’t specified behavior for edge case Z.” Detect inconsistency: “Constraint A conflicts with constraint B.”
Acceptance verifiers (the new test framework). Generate property-based tests from specifications. Report failures in terms of specification gaps, not code bugs.
Constraint checkers (the new linter). “This specification allows SQL injection.” “This spec implies O(n²) complexity.” “This specification violates organizational standards.”
Agent trace debuggers (the new debugger). “The agent chose algorithm X because...” “To change this behavior, modify your specification here...”
Source-level optimizers (the new optimizer algorithm). This one is critical and often overlooked. Traditional compilers optimize machine code—they eliminate dead code, inline functions, optimize memory access. We need the equivalent for source code generated by agents.
Why? Because agents generate slop. Without proper guardrails, an agent will happily write 200 lines of custom code instead of calling an existing library function. It will generate utility functions that duplicate what’s already in your codebase. It will ignore API boundaries and inline logic that should be abstracted. It will leave dead code paths, and so on.
Specification patterns (the new design patterns). Common patterns for specifying certain types of systems. Anti-patterns that lead to ambiguous specs.
Without these tools, we’re in the toggle-switch era of agentic development. Vibe coding is the default because specification engineering is too hard.
Building this tooling is the critical path.
What Future Engineers Need to Learn
So what skills matter in this upcoming world?
The skill shift isn’t from “technical” to “non-technical.” It’s a change in which technical skills matter.
Precise logical expression. Writing like a philosophy paper—arguments that are causal, trace to first principles. Avoiding implicit assumptions. The “else” must be stated.
Procedural thinking. Understanding how things iterate step by step. Sequencing matters. State changes matter. This is the old procedural programming skill, expressed in prose.
Interface design. How do you break down a problem? What are the boundaries between components? What does each part need to know about others? This is OOP thinking, without the syntax.
Success criteria design. This is the skill game developers have mastered for decades. How do you define “done” in a way that’s measurable, testable, and resistant to gaming?
Corner case anticipation. What happens at the edges? Empty inputs? Maximum scale? Concurrent access? Thinking like an adversarial tester of your own specification.
Systems thinking. How do parts combine into wholes? What emergent behaviors arise? Where are the failure modes? This is architecture, expressed in prose.
Fault-tolerant thinking. What can go wrong? What must not happen? Specifying constraints, not just capabilities. Graceful degradation of experience.
One-layer-down literacy. You must be able to read and understand generated code. Not write it from scratch, but audit it. Debugging still requires descent even if a futuristic debugger can help you.
Domain expertise. Agents don’t know your business. Translating domain knowledge to specifications becomes the irreplaceable human contribution.
Notice what’s changed and what hasn’t. The concepts are the same ones good engineers and builders have always needed. The medium changes from code to prose.
Implications for Education
If I were redesigning the CS curriculum today, I’d start by questioning the boundaries.
Right now, these disciplines live in separate departments:
Computer Science: algorithms, data structures, systems
Technical Writing: documentation, clarity, precision
Philosophy: logic, argumentation, ethics
Design Thinking: user needs, iteration, prototyping
Product Management: requirements, success metrics, trade-offs
Game Development: reward systems, progression, balancing competing objectives
In the agentic era, these all converge. They’re not separate skills anymore—they’re facets of the same core capability: specifying systems precisely and defining what success looks like.
Think about what agentic software engineering actually requires:
You need computational thinking to understand what’s possible and what’s hard. You need philosophy to construct logical arguments that trace to first principles—and to avoid the implicit assumptions that trip up specifications. You need technical writing to express complex requirements without ambiguity. You need design thinking to understand user needs and iterate toward solutions. You need product thinking to decompose business goals into measurable criteria. And you need game development thinking to design reward functions that don’t get gamed—success criteria that actually capture what you want.
These aren’t electives. They’re the core.
A CS major in the 2030s might look something like this:
Specification and technical writing. Before syntax. Expressing requirements precisely. Structured prose. Formal and semi-formal specification languages. This is the new “intro to programming”.
Computational thinking. Algorithms, complexity, trade-offs—but focused on recognizing and specifying, not just implementing. You need to know that something is O(n²) even if you never implement it.
Logic and argumentation. Borrowed from philosophy. Constructing valid arguments. Identifying hidden assumptions. Distinguishing necessary from sufficient conditions. This is the foundation of precise specification. The ability to be less vague about the world and the trade-offs.
Success criteria design. Borrowed from game development and product management. How do you decompose “good” into measurable outcomes? How do you balance competing objectives? How do you prevent gaming? This is reward function design as a discipline.
Verification and validation. How do you define correctness? Property-based testing. Acceptance criteria design. If you can’t define “correct,” you can’t verify it—and neither can an agent.
Human-AI collaboration. Specification engineering. Auditing agent output. Debugging specifications. Understanding when to sketch solutions vs. sketch success criteria.
Systems architecture. Composition, contracts, interfaces, failure modes. Essential for specifying complex systems, even if you’re not implementing them.
One-layer-down literacy. Reading and understanding code for auditing and intervention. You don’t need to be fluent, but you need to be literate.
Domain modeling. Translating domain expertise into formal constraints. This is the irreplaceable human contribution—agents don’t know your business.
Notice what’s missing from the traditional curriculum: hours and hours of syntax drilling. Implementing sorting algorithms from scratch. Memorizing API signatures. These become less important when agents handle implementation.
And notice what’s elevated: writing, logic, criteria design, systems thinking. The humanities and the technical converge.
The meta-skill? Learning to learn new abstraction layers. More are coming. Adaptability is the durable advantage.
I’m not saying we throw out algorithms and data structures. You still need to recognize an O(n²) disaster when you see one. You still need to understand why certain architectures fail at scale. But the emphasis shifts from implementing to specifying and evaluating. Plus all the underlying layers will still be evolving and there will be a need for such specialists. Also, programming courses are the only thing we have currently developed for mass consumption. So, in the future, I’d move courses on programming language and compilers or operating systems and networks or linear algebra and ML algorithms into electives, and not part of a core curriculum. Most engineers won’t need them.
The CS department of the future might need to poach faculty from Philosophy, from the Design school, from the Game Development program, from Technical Communications, and Business Schools. Or maybe we stop pretending these are separate disciplines at all.
The “Fit in Your Head” Test
Here’s the ultimate measure of each abstraction layer: how much complexity can one engineer manage?

The pattern is clear. You stop holding implementation details. You start holding contracts, interfaces, specifications. The scope expands because the abstraction compresses.
If agentic tooling matures, a single engineer might specify systems that currently require teams and years of work. Not because they understand every line of code, but because they understand the specification layer and trust verified translation through the stack. We have to equip a single individual with the mental models, skills, and tools to design, implement and deploy things like a database from scratch, or the whole software package of a space station, or the energy management system for a smart city, or a service as complex as Uber.
This is the opportunity. And the challenge.
Democratization: Why This Time Might Be Different
Now let’s talk about what this means for who can build software.
Programming has historically been gated by several barriers:
Syntax mastery. Memorizing language rules, keywords, punctuation.
Tooling complexity. Setting up development environments, dependencies, build systems.
Error interpretation. Understanding cryptic compiler messages.
But the deepest barrier is harder to see: learning to think like a machine.
Even “high-level” languages expose the underlying computer architecture. To write code properly, you must understand concepts shaped by hardware:
Compute: What operations are cheap vs. expensive?
Memory: Stack vs. heap, allocation, garbage collection, references vs. copies
Execution: Sequential flow, call stacks, control transfer
I/O: Blocking vs. non-blocking, streams, buffers
Concurrency: Threads, locks, race conditions
These aren’t “advanced topics”—they leak into everyday programming decisions. “Should I load this into memory or stream it?” “Why is this loop slow?” “Why did this work locally but fail in production?”
You’re not just learning a language. You’re learning to inhabit an alien worldview.
It’s like learning a foreign language well enough to write legal contracts—but for a client whose mind works completely differently from yours. Most people who “learn a language” in school can order coffee. Most people who “learn to code” in a bootcamp cannot build a coffee-ordering app. The gap to professional fluency is vast.
What LLMs change:
Previous democratization attempts—visual programming, no-code tools—lowered syntax barriers but still required upfront precision. You still had to think like a machine.
LLMs change the workflow fundamentally:
Non-deterministic generation approximates intent
You can describe patterns, not just lines
You see working sketches before committing to details
Rapid refactoring reduces wrong-path risk
This matches how artists work. Sketch → shape → refine → detail. Traditional coding inverted this: detail → detail → detail → test → detail.
The medium now supports the workflow that was previously only available to experts.
The workforce implication:
If the expert workflow is accessible to novices, and syntax barriers are removed, and wrong paths are low-cost to abandon... the pool of potential software creators expands dramatically.
Not 10% more programmers. Potentially 10x more.
Domain experts can implement their ideas directly. The “idea person” and “implementation person” can be the same person. The gap between concept and working demo shrinks.
The nuance:
This doesn’t democratize everything equally.
Democratized:
Producing working code (syntax barrier gone)
Building simple applications (sketch-level work)
Prototyping and exploration (low iteration cost)
Not equally democratized:
Building robust, production systems (requires specification rigor)
Handling use cases and failure modes (requires systematic and user-centric thinking)
Architecture and system design (requires deep understanding)
The skill bar shifts. It doesn’t disappear.
Think about spreadsheets. They democratized computation in the 1980s. Non-programmers could suddenly do sophisticated data manipulation. But complex spreadsheet modeling still requires skill. And spreadsheets can still go badly wrong—ask anyone who’s seen a financial model with circular references.
Excel didn’t eliminate the need for financial analysts. It changed what they do.
Agentic coding may follow the same pattern. What a senior engineer learns from 20 years of experience will become table stakes for new grads.
Open Questions
I want to be honest about what we don’t know.
Where will the agentic abstraction leak? Every layer leaks. Prediction: specification ambiguity, edge cases the spec didn’t anticipate, performance local optimals from agent choices, security vulnerabilities from underspecified constraints. We’ll be fixing those over time one by one.
What’s the new “dependency hell”? Composition had dependency conflicts. Declarative has config drift. Agentic might have: specification inconsistency across systems, agent version drift (same spec, different outputs), non-reproducible generations, LLM prompt or RAG dependency conflicts in large agentic systems. One module says A, the other says B. Which version does the agent use?
How do we build trust? We trust compilers because they’re deterministic and formally verified. Agents are stochastic—same input can produce different output. On top of that we choose what memory to attach to them and hope we context-engineered it well. How do we get compiler-level trust for something fundamentally probabilistic? We are barely scratching the surface on how to compartmentalize agent outputs in real-world apps.
Does this democratize or stratify? On the optimistic side, more people can build complex systems. On the other hand, a new elite of “specification whisperers” could emerge. I think both are happening. The floor rises (more people can do more) and the ceiling rises (experts can do even more).
Timeline? This evolution could take 5 years or 20 years. Depends on tooling development, trust building, education system adaptation. The pattern is clear; the timing is not because funding is limited, society needs time to adjust, and investors and politicians are human.
What We Need to Do Now
If this analysis is right, here’s what matters:
Build the tooling. Specification validators, acceptance verifiers, constraint checkers, agent trace debuggers, source code optimizers. This is the critical path. Without tools, vibe coding remains the default.
Update education. Emphasize specification, verification, and writing. Maintain one-layer-down literacy. Teach mental models, not just syntax.
Develop trust mechanisms. Figure out how to get compiler-level confidence from stochastic systems linked to memory and data. This is an unsolved research problem.
Create patterns and practices. What does good specification engineering look like? Or “definition of done” design? What are the anti-patterns? We need a discipline, not just a set of tricks.
Closing Thought
The practitioners of every era believed they were doing “real” programming.
The assembly wizards who hand-optimized register allocations. The C programmers who understood the stack. The Java architects who drew UML diagrams. The Node developers who composed npm packages.
They were all right—for their era.
The agentic generation will be no different. The engineers who thrive will be those who can say precisely what they mean and verify that they got it.
The pattern that has held for 70 years continues. Each generation fits more in their heads and builds bigger things. The medium changes. The fundamental challenge—translating human intent into machine behavior—remains.
History rhymes. The next verse is being written now.
And I think we have a say in how it sounds.