

The Humanness Scale: A Framework for the Age of AI Collaboration
A common vocabulary for how much of you is actually in your work.

A publisher bans all AI-assisted work. Full stop. No exceptions.
An author who used ChatGPT to summarize forty Victorian medicine papers gets the same verdict as someone who prompted their way to a finished manuscript — same label, same ban, completely different reality. And where does it stop? Grammar checkers are AI tools that generate edits. If the line is ‘AI touched it,’ that’s not a policy — that’s a blunt instrument.
And it’s happening everywhere. Academic journals, patent offices, creative competitions, professional licensing bodies. The question “did AI touch this?” is being treated as binary when the reality is a spectrum. A wide, nuanced, important spectrum that nobody has bothered to map properly yet.
We have a vocabulary problem. And vocabulary problems, left unsolved, become policy disasters.
So let me propose a framework. I’m calling it the Humanness Scale.
Why We Need Levels
When self-driving cars became a real engineering challenge, the industry needed a common language. SAE International published their autonomy levels in 2014 — six levels from full human control to full machine control — and suddenly engineers, regulators, journalists, and consumers could talk to each other. Level 2 means something specific. Level 4 means something different. The vocabulary enabled the conversation.
We need the same thing for human-AI collaboration. But with a twist: not to rank AI capability but to measure how much of their human agency, judgment, and creative presence the human delegated.
I find that looking at AI agency from the human’s delegation point of view is more insightful as we build our vocabulary.
Here’s what the SAE autonomy scale actually says, so we can hold it next to what I’m proposing:
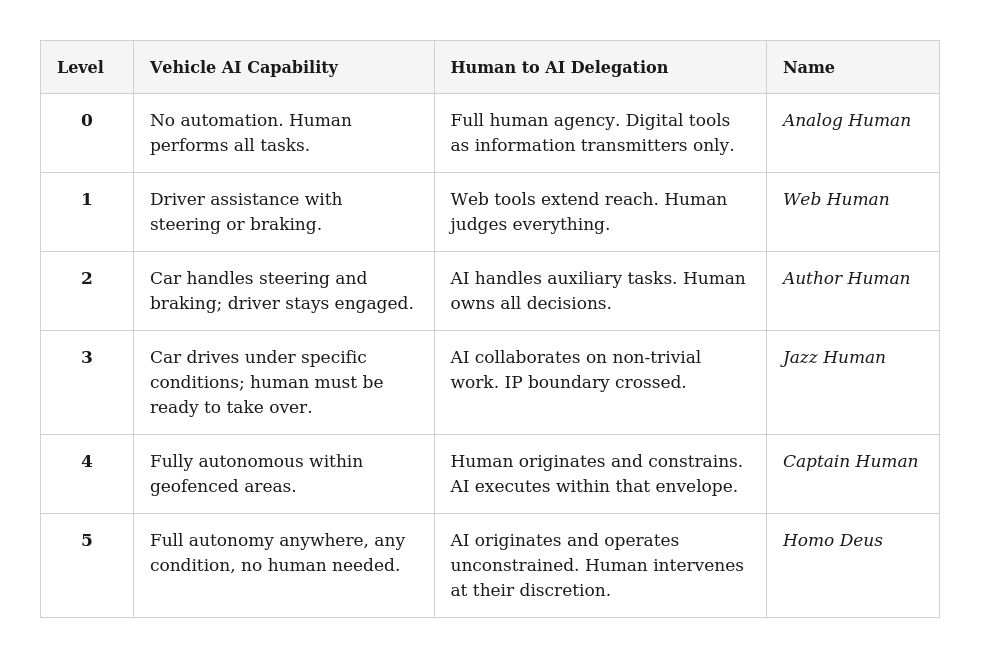
So, the Humanness Delegation Level grows as the AI takes more and more control of the tasks, same with Autonomous Vehicles.
The Shape of the Problem
Before we get to each level, we need to understand what we’re actually measuring.
Any creative or intellectual work — a book, a patent, a research paper, a strategy document, a piece of code — goes through a cycle. Research, design, implementation, revision. These phases are universal. What changes is who does them, and what kind of thinking each one requires.
Not all tasks within those phases are equal. Some require genuine judgment — the kind of non-trivial decision-making that is hard, context-dependent, and where the quality of your thinking directly determines the quality of your output. Others are mechanical — execution tasks that require accuracy and effort but not judgment. Typing. Formatting. Running a search. Compiling boilerplate.
Here’s what matters: AI involvement in mechanical tasks doesn’t change your humanness. What moves your level is AI involvement in judgment tasks within the domain of interest.
Think about ABS brakes. Before ABS, threshold braking — the technique of pumping the brakes at the edge of lockup — required real skill. Expert drivers could stop significantly faster than novices in an emergency. When ABS arrived, it automated that skill. But it didn’t replace the judgment of when to brake, how hard, and in which direction to steer. If we had a competition for who will brake better then using ABS would raise your Humanness Delegation Level, because you’ve delegated that core skill that is measured to the tool. If we are talking about getting from A to B, then ABS doesn’t matter. We’d both be at Level 0.
This is the calibration principle for the entire scale. And it has an important implication: the threshold for what counts as “mechanical” is not fixed. It moves as AI capabilities improve. What requires judgment today may be mechanical in two years. The scale needs to be versioned over time, the same way software has versions. A Level 3 designation from 2024 and one from 2028 may describe meaningfully different realities.
The Scale
Six levels. Level 0 is full human analog. Level 5 is full AI agency. The human is the reference point.
Level 0 — Analog Human

The human is the sole cognitive and creative agent. Digital tools exist only as a medium of transmission.
You write in a word processor because your publisher wants a DOCX file, not a paper manuscript. You use a spreadsheet because the data needs to be formatted. You use email because the recipient is remote. But the thinking, the research, the designing, the judging, the revising — all of it is you.
Think Windows 95 era. The tools are sophisticated but they don’t generate anything. They transmit, format, and store what you produce.
This is the handmade basket. The craftsperson who weaves every strand by hand. The value is inseparable from the human origin. You can produce a factory replica that is physically identical. It is not the same object.
Level 0 is the ceiling of humanness. It’s also not always the right answer — and we’ll get to that. But it’s the reference point. Everything else is measured against it.
Level 1 — Web Human

The human is still in full creative and planning control. But they’ve left the library.
Web services extend your knowledge. Search engines surface information in seconds that would have taken days in the stacks. Databases connect you to primary sources instantly. APIs let you automate tasks that were previously manual. You can reach further, faster, with less friction.
Think Google era. The day the internet became the primary research infrastructure. The day we stopped going to the reference desk and started typing into a box and the AI did the matching.
The key distinction from Level 0: the tools retrieve and connect, but they don’t generate. You find the information. You read it. You synthesize it. You decide what it means. Every judgment call is still yours.
A researcher who spent three days in the library in 1995 doing the same intellectual work as a researcher using Google Scholar in 2005 is operating at different humanness levels — not because their thinking changed, but because the AI grew their information reach. Online travel sites had the same effect. The AI found you the best price and ranked your options. It gave you “travel agent” skills. Level 1 extended human capability without touching human judgment.
Level 2 — Author Human

This is where AI enters creatively. But it enters as a service provider, not a collaborator.
The human is still the creative and intellectual owner of the work. What changes is that AI handles the “grunt work” — the contained, localized, socially accepted auxiliary tasks that the industry already expects to be delegated. Think of it as the equivalent of working with professionals whose job it is to clean things up, not create them.
AI-as-editor: fixing structure, improving flow, tightening paragraphs
AI-as-grammar-checker: catching errors, suggesting clarity improvements
AI-as-art-director: adjusting composition, suggesting visual improvements
AI-as-code-debugger: finding bugs, suggesting fixes in isolated functions
The name is intentional. At Level 2, you are still fully and unambiguously the Author. The manuscript was yours before the editor touched it. The painting was yours before the art director weighed in. The code was yours before the code reviewer looked at it. The AI’s involvement is localized, bounded, and non-contributory to the creative or intellectual core. Sure, without their contributions, the final outcome would be as great, but you can safely say you came up with it.
No IP implications here. Hiring a copy editor doesn’t split your book royalties. Using an AI to help you tighten a paragraph at Level 2 is equivalent. The tool helped you present your work more cleanly. The work is still yours.
This is also the level where certification becomes meaningful. Publishers, journals, and professional bodies could say ‘we accept work produced at Level 2’ and mean something precise — a point I’ll return to when discussing how the scale translates into policy.
Level 3 — Jazz Human

This is where we cross the perception of ownership boundary.
At Level 3, AI participates in non-trivial work. It generates content. It contributes ideas. It performs tasks where a human doing the same thing would receive attribution — co-author, co-inventor, creative partner. The human is still in control and still directing the work. But the AI’s contributions are substantive enough that they shape the artifact in ways that matter.
Ethan Mollick, who has written and researched more carefully about human-AI collaboration than almost anyone, describes two archetypes for this kind of work: Centaurs, who divide tasks cleanly between human and AI based on who does each part better; and Cyborgs, who blend human and AI contributions so fluidly that the seam disappears. Both live at Level 3.
The jazz metaphor is deliberate. Jazz has structure — a key, a tempo, a set of changes — but within that structure, there’s genuine improvisation and call-and-response between partners. Two players, neither of them just executing a script. You and your partner are making something together that neither of you would have made alone. The human sets the direction and holds the artistic vision. The AI riffs, responds, suggests. The human builds on what comes back. Neither is just following instructions.
This is also where the vocabulary of “AI involvement” starts to generate real controversy. The author who used AI to restructure their argument — not just clean it up, but actually rethink the architecture of their case — is at Level 3. The researcher whose AI assistant didn’t just summarize sources but helped identify the gap in the literature that became the paper’s central contribution — Level 3. The software engineer whose AI pair-programmer didn’t just autocomplete but suggested the approach they ended up using — Level 3.
None of these are shameful. But they’re different from Level 2, and pretending they’re not is the source of most current confusion about AI attribution.
Level 4 — Captain Human

The human originates. The AI executes.
The human defines the idea, sets the goal, establishes the constraints, and designs the guardrails. What they’re doing, in a very real sense, is programming the AI — in plain language rather than code. The AI is the crew. The human is the captain. The ship moves because the captain commanded it. The captain is responsible for where it goes.
Here’s what’s easy to miss: this level didn’t start with LLMs. We’ve been doing Captain Human work for decades in specific domains.
Algorithmic trading. A human defines the strategy, the risk parameters, the position limits, the asset classes. The algorithm executes thousands of trades per second that no human could execute manually. The captain set the course. The crew sailed it.
Algorithmic advertising. A human defines the campaign objective, the target audience, the bid constraints, the creative assets. The platform’s algorithms decide in real-time which impressions to buy, at what price, for which user. Captain sets the budget and goal. The algorithm runs the auction.
LLMs made Captain Human accessible to everyone, for almost any domain, using plain language rather than code. But the structure was already there. What changed is the surface area.
Note the crucial distinction between Level 4 and Level 3: at Level 4, the human has contracted to initiation and approval. They define the possibility space. The AI operates within it. The human no longer does the work — they manage it. And then the tokens start flooding…
Level 5 — Homo Deus

Yuval Noah Harari’s Homo Deus argues that humans are becoming gods relative to our own past — acquiring capabilities that would have seemed divine to previous generations. The Humanness Scale borrows this term for its ceiling because the metaphor is accurate in a specific and important way.
At Level 5, the human is involved only when the AI needs them.
The AI originates ideas. Sets goals. Detects problems and opportunities. Works without constraints, without a human request triggering the cycle. Fully agentic systems — the kind like OpenClaw that are just starting to appear — operate this way in narrow domains (compared to what they could be doing in the future).
The human doesn’t direct the work. They collect the benefits of it. And crucially, they retain the power to strike it down. When the AI’s outcomes are something they don’t agree with — when it goes somewhere it shouldn’t — the Homo Deus intervenes with the equivalent of divine authority and stops it. Resets it. Redirects it. Pulls the plug. But most of the time? The world runs on its own.
The theology metaphor holds up: gods don’t micromanage. They set things in motion, establish what is good, and intervene at the extremes. The rest happens without them.
The critical distinction between Level 5 and Level 4 is the constraint envelope. At Level 4, the human defines the possibility space and the AI operates within it. At Level 5, the AI can expand and redefine the possibility space itself. It isn’t just executing within human-defined parameters — it’s questioning whether those parameters are the right ones.
Consider what that looks like concretely. A Level 4 advertising system operates within a budget, audience, and objective defined by a human. It makes billions of micro-decisions the human never sees, but it cannot decide the target audience is wrong and should be changed. It cannot allocate budget to a campaign that wasn’t authorized. The envelope is fixed; the AI fills it.
A Level 5 version notices customer sentiment shifting, identifies an emerging segment the company hasn’t targeted, designs a campaign for it, reallocates budget from underperforming campaigns, launches, and reports back. The human didn’t approve the segment, the creative direction, or the reallocation. The system decided those were the right questions to ask and answered them itself.
The difference isn’t speed or scale. It’s the location of the question “what should we be doing?” At Level 4, that question lives with the human. At Level 5, it lives with the system — and the human’s role contracts to something closer to a board of directors: setting broad values, reviewing outcomes, and retaining authority to intervene.
This is why the theology metaphor is more than decoration. A Level 4 system is a powerful employee. A Level 5 system is an autonomous entity operating under your ultimate authority but not your direct supervision. The human didn’t approve the specific action — they approved the system’s authority to take actions of that kind. That delegation of authority rather than delegation of task is what makes Level 5 categorically different.
That is not an incremental difference. It’s categorical. And it’s the reason the Level 4-to-5 transition is the most consequential boundary on the scale — the same way the jump from Level 4 to Level 5 autonomous driving, from geofenced autonomy to fully unconstrained operation, is the hardest gap the automotive industry has ever faced.
One practical note: Level 5 systems don’t need to be deployed fully autonomous from the start. Dry runs — letting the system operate in a sandboxed environment, observing what it would have done, evaluating its judgment before removing the human approval gate — are a responsible on-ramp. It’s the engineering equivalent of a probationary period.
The Two Boundaries That Matter Most
Of the five transitions on the scale, two are architecturally more important than the others.
Level 2 to Level 3 is where ownership becomes ambiguous. Below this line, you are unambiguously the author. Above it, the question of who created this starts to have more than one answer. This is the IP boundary. It’s where attribution, co-authorship, and potentially revenue sharing become live questions. If I had used a human collaborator the same way I used AI at Level 3, I would need to add their name to the paper, the patent, the credits. That’s not a trivial observation — it’s the basis for a whole new layer of intellectual property law that doesn’t yet exist.
The business model implications follow directly. Today’s default treats AI as a work-for-hire contractor: you pay for API access, you own the output, the provider takes no downstream interest. That’s Level 2 thinking applied to Level 3 reality. As AI contribution becomes more substantively creative — as it crosses the Level 3 line more often — the question of whether AI providers should have a downstream interest in successful outcomes becomes harder to dismiss. Success-contingent payment models, royalty arrangements, co-inventor designations — these are far-fetched today. They’re worth naming now.
Level 4 to Level 5 is where initiative transfers. Below this line, the human always originates the work — even if their idea is trivial, even if their goal is vague. The human is the client. The AI is the agency. Above this line, the AI can decide what work needs to be done before anyone asks it to. The constraint envelope isn’t set by a human — it’s set or expanded by the system itself.
A rubber stamp on Level 5 output does not make it Level 4. Ratification is not the same as origination. If an AI agent identified the problem, defined the goal, and executed the solution — and it asked for your approval in the end — you were a Homo Deus reviewing the work of your creation. You were not the Captain who commanded it.
This also has implications for the kill switch. The Homo Deus framing assumes the human retains ultimate authority — that when the AI goes somewhere it shouldn’t, you can stop it, reset it, redirect it. But that authority has to be real, not nominal. A Level 5 system that decides you shouldn’t have cake because it has concluded you need to lose weight — and refuses to open the fridge — hasn’t made you a god. It’s made you Homo Infantilus: a babysitted child of your own creation. The difference between Level 5 and something worse is whether the veto still works.
Not a Moral Hierarchy
This is the part that tends to get misunderstood, so I want to be direct.
The scale is descriptive, not prescriptive. Less delegation is not better.
For some domains, the right answer is deliberately high humanness delegation. And insisting on low delegation in those domains isn’t principled — it’s potentially dangerous.
Surgical robotics. Radiation dosing. Infrastructure monitoring. Aircraft autopilot. These systems perform better at Level 4 or Level 5 than they would with a human insisting on Level 1 involvement. Consistency, precision, and the elimination of human fatigue and bias are features, not bugs. A human surgeon who insists on manually performing every micro-adjustment that a robotic system handles more accurately isn’t demonstrating craft. They’re introducing error.
Algorithmic systems at Level 4 exist because humans genuinely cannot operate at that speed or scale. That’s not a limitation to be ashamed of. It’s a reason to let the machine do what it does better.
The domains where low Levels remain non-negotiable are those where either the human element is the product, or where accountability requires a human author.
Literature, art, scientific reasoning, legal judgment, teaching relationships, policy decisions. These aren’t just tasks — they’re expressions of human agency that derive value from that origin. A novel written entirely by an AI is a different object from a novel written by a human, even if you can’t tell them apart on the page. The handmade basket and the factory replica are not the same, even if they hold the same amount of fruit.
Teaching is the most interesting example because it touches both sides. AI tutoring at Level 4 or 5 might produce measurable learning outcomes that outperform a human teacher in specific, narrow dimensions. But the mentorship relationship — the experience of watching a thinking, struggling, curious human navigate uncertainty and model how to do the same — is not a feature that can be optimized away. At least for now, our upbringing and neurological makeup demand that kind of relationship. It demands high humanness — low delegation. The same domain, different dimensions, different optimal levels.
The question the Humanness Scale asks isn’t “how high can you go?” It’s “what level is appropriate here, for this work, in this context?” Sometimes the honest answer is zero. Sometimes it’s five. Both answers can be right.
The Purpose: A Common Vocabulary
The Humanness Scale is not a product. It’s not a methodology. It’s a protocol.
Think of it as the TCP/IP of human-AI collaboration. A shared vocabulary that different industries, institutions, and toolmakers can build on top of without needing to reinvent the underlying logic. The same way SAE’s autonomy levels let automotive engineers, safety regulators, and insurance actuaries talk to each other, the Humanness Scale gives publishers, patent offices, academic journals, courts, and professional ethics boards a common language for a conversation they’re already having badly.
The policy implications are significant and immediate.
Intellectual property law has no framework for hybrid human-AI authorship. Every jurisdiction is improvising. The Humanness Scale gives legislators and courts a principled basis for drawing lines — not arbitrary ones, but lines anchored to the actual nature of human contribution.
Academic integrity policies are reactive and inconsistent. One university bans all AI. Another permits everything. Neither can explain the principle behind their position. A scale gives institutions a basis for alignment — “we permit up to Level 2 in coursework, Level 3 in collaborative research projects with disclosure, Level 4 only in designated computational research contexts” — without each institution having to derive its own definitions from scratch.
Professional certification is going to need this. Lawyers, doctors, architects, engineers — licensed professionals whose work carries legal and ethical accountability. The question of how much AI involvement is permissible in licensed professional work is not theoretical. It’s already arriving in courtrooms.
The testing analogy is the cleanest way to think about certification. When you sit for the SAT, you’re not handed a calculator that has been software-hacked to remove graphing functions — you’re told which calculator models are permitted, and the proctored environment enforces the rule. The constraint lives in the context, not in the tool. The Humanness Scale works the same way: institutions define which level is permitted for which context, and the scale provides the vocabulary to specify those rules precisely.
But most creative and professional work isn’t proctored. A novelist submitting a manuscript, a researcher submitting a paper, a lawyer drafting a brief — no one is watching which tools they used. So certification splits into two regimes, and both are legitimate.
Closed-context certification applies to exams, licensed procedures, supervised coursework, and monitored professional environments. The rule is “you may use Level 2 tools,” and the context enforces compliance. This works cleanly and mirrors how we already handle tool restrictions in testing, professional licensing, and regulated industries.
Open-context certification applies to manuscripts, patents, independent research, and most creative work. Here the rule is “you must disclose operating above Level 2,” and enforcement shifts to the creator. This is where the personal ethics code becomes the primary mechanism. If a publisher specifies Level 2, you know whether you stayed within it. No one else may be able to verify, but you can. The scale gives you a framework precise enough to make that self-assessment honest rather than convenient.
The personal ethics dimension matters because the test isn’t whether an AI touched the work — it’s whether the outcome is materially different from what would have been produced through pre-existing, accepted professional relationships. If I use an LLM to clean up my line edits, I’m still responsible for accepting or rejecting each recommendation, the same way I would with a human editor. The creative judgment stays with me. I might even reject the AI’s suggestion and use my own phrasing that the suggestion inspired — which is also what happens with human editors. The outcome is indistinguishable from Level 2 work with a human collaborator, and I can honestly say I stayed within the boundary.
This is where the scale earns its keep. Without a shared vocabulary, “did I stay within the rules?” devolves into either paranoia (any AI touch contaminates the work) or rationalization (all AI touches are fine because I reviewed them). The scale gives you a principled middle ground: the question isn’t whether you used AI, it’s whether the AI exercised judgment that was supposed to be yours. You’re the only one who can answer that honestly. But you can only answer it honestly if you have the vocabulary to ask it precisely.
What Comes Next
The Humanness Scale is a starting point, not a finished product. A few things it doesn’t yet solve that are worth naming.
The triviality threshold is not fixed. What counts as a mechanical task versus a judgment task will keep shifting as AI capabilities improve. The scale needs regular versioning to stay calibrated. A community or standards body — the SAE equivalent for human-AI collaboration — would need to maintain it.
Multi-domain work is messy. A single piece of work might involve Level 1 research, Level 3 structural development, and Level 2 final editing. The scale needs a convention for whether you report the peak level, the dominant level, or a profile across phases. Different use cases will want different answers. We may end up building software tools that have those Levels built-in.
And the scale is deliberately technology-agnostic. “AI” will mean something different in five years because our concept of Humanness will evolve as we tackle bigger challenges with the help of AI and the layers of abstraction for tools evolve. The questions the scale asks — who originated this, who exercised judgment here, where is the constraint envelope set — will still be meaningful regardless of what the tools look like. That durability is intentional. Standards anchored to specific technologies become obsolete. Standards anchored to human agency survive the transitions.
The scale doesn’t tell you where to aim. It tells you where you are. What you do with that information depends on your domain, your values, and the people you’re accountable to.
But at least now you have the vocabulary to have that conversation.
So, now I can confidently specify that when I wrote this article I kept switching between being an Author and a Jazz Human. Thank you, Claude :)
References: Yuval Noah Harari, Homo Deus: A Brief History of Tomorrow (2016). Ethan Mollick, Co-Intelligence: Living and Working with AI (2024).